
Beyond the Basics: Designing for a Million Users
Add to your system design knowledge toolkit! These are concepts, which every engineer must know, if they want to scale from zero to millions of users or ace their interviews!


Hello guys, if you are preparing for system design interview or just want to level up your Software Skills then you have come to the right place.
Earlier I have talked about common system design concepts like Rate Limiter, Database Scaling, API Gateway vs Load Balancer and Horizontal vs Vertical Scaling, Forward proxy vs reverse proxy as well common System Design problems and concepts like Single Point Failure, and in this article we will talk about how to design systems which can withstand million users.
For this article, I have teamed up with Konstantin Borimechkov and we'll dive into the fundamental concepts of designing and scaling system to million users.
By the way, if you are preparing for System design interviews and want to learn System Design in a limited time then you can also checkout sites like Codemia.io, ByteByteGo, Design Guru, Exponent, Educative and Udemy which have many great System design courses
Similar, while answering System design questions you can also follow a System design template like this from DesignGurus.io to articulate your answer better in a limited time.

Now, over to Konstantin Borimechkov to take you through to the article.
Inspired by ByteByteGo founder Alex Xu‘s Book on System Design Interview, I decided to write this blog as a summary of my understanding from the first chapter of Vol.1!
Take this blog-post as notes I took from the book.. but very valuable ones. 📚
That said, you can use this as a summary or quick reference to some core principles we should go by when designing an application. Or when preparing for system design interviews - up to you 🙌
⚠️ Disclaimer: There are many things that go into developing and scaling a system, which won’t be mentioned in this blog-post as I don’t want it to get lengthy.
That said, I will try to be precise and informative here. Expect deeper dives in future blog-posts & subscribe if you wanna get more of these! 🙏
Our Basic App
So, here is the situation, we have zero to no experience with architectures and programming. But we heard a few things from here and there:
we need a server to host my code, which serves content to the user
we need an infrastructure to host this server in - on-prem or in the cloud
we also want to have some neat domain name like google.com, so we need to buy that from some DNS provider

After creating the app and having some traffic we start to experience some issues.. 😬
Lets say we have a LinkedIn-Like app and we get a surge of users, which start posting and reading posts.
As more and more users start to post and read posts, the single server that we have gets increasingly more requests coming, which increases the latency of our application and effectively makes the app slower. Imagine waiting to see your LinkedIn Feed every 10s as opposed to 10ms 🥴
an incident happened on Monday and the whole application crashed
we need to constantly go to AWS and increase the CPU and Storage Limits
Last month we got an unexpected bill from AWS because someone DoS’d my service..
Some users from Asia complained that everything is very slow on their end, while users in Bulgaria didn’t have such issues 🤔
.. well, these are SOME of the issues we will face if we don’t incorporate proper scaling techniques and architect our application to scale.
An Application That Scales To Millions Of Users
To avoid the above mentioned issues, we can utilize the wide range of tools and techniques, found by many amazing and talented engineers all around the world.
Vertical Vs. Horizontal Scaling
The approach described above is using vertical scaling. And that is exactly why the app faced the Single-Point-Of-Failure problem (if one server goes down, the whole app goes down), the constant AWS CLI trips and all else..

Vertical scaling is when you have a single instance of your app running and everything is coupled inside of it.
Limiting the scaling opportunities to only being able to increase the size of the instance (CPU, RAM, Storage..).
With Horizontal Scaling on the other hand, you have multiple instances of your service running. You can scale by adding more instances and distributing the traffic among them. This way you can can handle much more users.
You can read more about horizontal and vertical scaling here

But how do you distribute this traffic?
Stateful Vs. Stateless
Without going into too much details here.. modern applications are stateless.
Stateless applications don’t keep users state per server. In stead they used a shared data source, like some NoSQL database, which acts as a storage of user session data. Different servers can connect to this DB and get the user session at any time!
Stateless apps are easier, more robust and effectively much easier to scale horizontally!
You can read more about stateless and stateful architecture here

BTW 👀 If you want any help with your interview process and potentially 2X-ing your salary, checkout TopCoding! We have a Mentorship Program & Discord community with like-minded and goal-driven engineers!
Load Balancing
Serving traffic to multiple instances adds the question: How do I decide to which instance I should route each request?
Well, here comes the Load Balancer!
The Load Balancer gives us the opportunity to smartly pick which instance/server to route each request to. It does that by a pre-defined algorithm.
The most basic one being the Round-Robin one, where we simply have a list of servers and the load balancer routes each request to the next server in-tern.
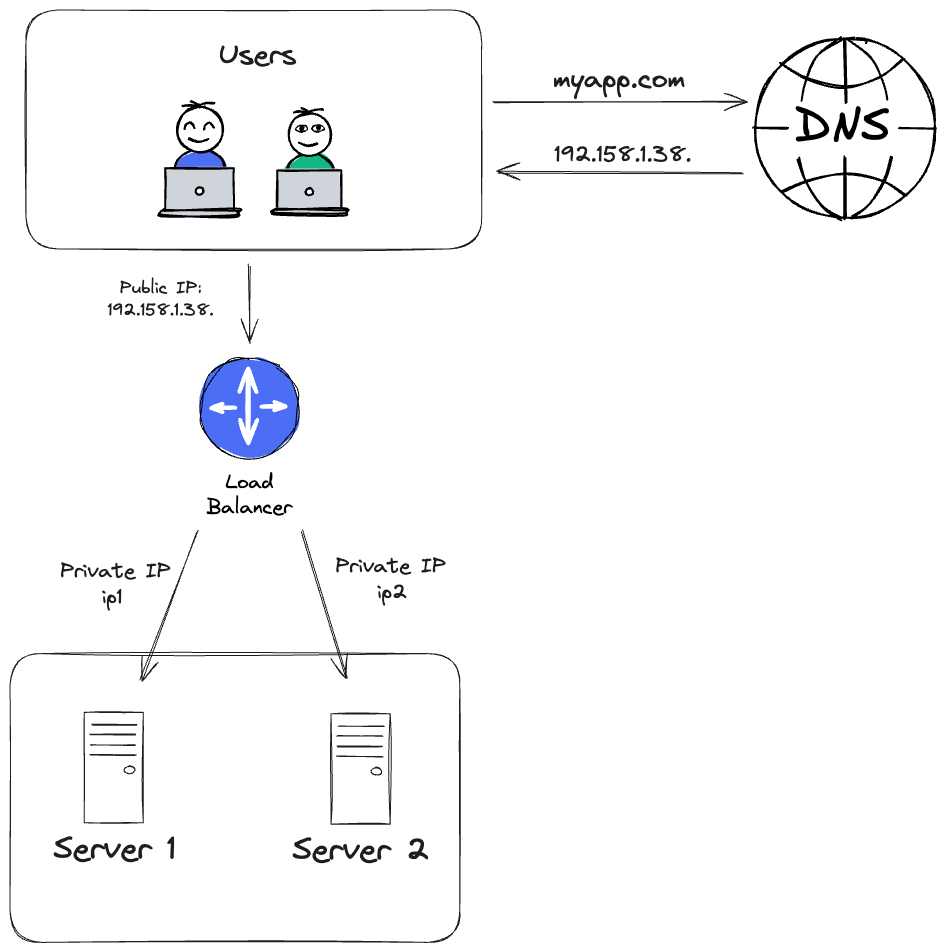
And voila, we can know distribute traffic across multiple instances and effectively, to scale horizontally! Well.. not at all TBH 😆
The Load Balancer also acts as a safe-guard, as it communicates with the server over private IP addresses. The client sends the public IP that they got from the DNS and the LB routes it to the appropriate private IP network address.
Picking A Correct Database
Now, one of the most important things when it comes to databases is - which type of database are you going to use? A relational one like Postgres?
A non-relational one? A wide-column, key-value, graph, document or which other type of NoSQL? 🥴
These are very large questions, which largely depend on what’s your app doing. In general:
If you need strong consistency of data or/and have a lot of data relationships - use relational
If you need a lot of scale and are okay with data being more eventually consistent - use NoSQL
🔗 I have a whole article on Strong Vs. Eventual Consistency here!
Scaling The Database
Well let’s first separate the database from the code, otherwise we won’t be able to scale it independently from the servers keeping our application logic (code) .

Almost Perfect. Now we can utilize a whole bunch of tools to scale the DB independently from the server itself. Lets briefly discuss replication & sharding, as they are one of the 🔑s for massive scale!
Replication

With replication, we move from having one instance holding our DB to multiple once. There are various ways to do that, but let’s look at the master-slave model with two slave nodes.
Nodes in that case are instances holding a replica of the DB.

⚠️ Note, this is one of the many ways to do replication across different nodes
Master - this node will support all WRITE operations (i.e. UPDATE, DELETE, INSERT..)
2 Slaves - these nodes will support only READ operations
Most applications have an unbalanced WRITE:READ ratio. Depending on this balance we can pick whether we need more master or slave replicas. Each design holds it’s own trade-offs, which will be discussed in future blog-posts.
What we get from this replication?
Scaling WRITE instances independently from READ ones and vice-verse
READs don’t make WRITEs slow and vice-verse, as they are in separate nodes (the have different CPU/Memory/Storage)
Data Consistency - massive topic here, but to sum it up, we need data replicated across all nodes. Since data is written to master node, it needs to send this data to all other slaves. Here we need to make the choice of eventual vs strong consistency again - i.e. is each request going to wait for all nodes to get the updated data or we can go even if there is some READ replica that didn’t get updated? 🤔
Replication brings a lot of overhead in terms of configuring and maintaining it[
Sharding
Our database grows and some tables get pretty big. So an amazing idea pops - why don’t we split the table into multiple separate tables, each holding a piece of the whole data?
Well, that’s what sharding is.
‘Sharding is a technique that addresses the challenges of horizontal database scaling. It involves partitioning the database into smaller, more manageable units called shards.’ - from this ByteByteGo blog-article on Sharding
To shard a table, we need some key, called shard key, based on which we can separate this table.
Let's pick the `user_id`.
Now, we need to decide on an algorithm that will use this shard key and distribute the piece of data to the result (which is the `shard_table_id` that we get from the algo).
Here we can talk about Consistent Hashing and all, but tbh I haven’t reached that stage of the book, so I will keep it for future blog-posts.. 📌
Caching
Our app has been running for some time and we observe that there is a lot of the same data, being read over and over again. What can we do? Add Caching 🚀

Caching is our next tool - it’s an in-memory key-value data store, that is perfect for frequently access memory. With caching data is stored in-memory and not on disk, which makes accessing it much much faster.
But why don’t we store all data in the cache then? 👀
The memory - RAM, where cache is stored is much smaller in size compared to disk
Very expensive - using the RAM is much more expensive than using the disk in terms of $
Volatile memory - if the server crashes or some failure occurs, the RAM is flushed-out and all data stored in it is lost
These are just some concerns and we won’t go into much depth here.
Deciding on a cache strategy for our data
1st: How are we going to store data in cache? This blog-post explains all ways we can do that! Again, kudos to ByteByteGo for the amazing infographics!
2nd: When are we going to remove data from cache? Here is a blog-post the described all ways of evicting data form cache

❗️Due to size-limits of this blog-post, I will be adding all of the above components onto the design we’ve been crafting above and provide it at the end of the blog-post, under `Final System Look 👀`
CDN
A Content-Delivery-Network is another component, which anyone can add to their system. But why??
Because with CDNs you can get instant retrieval of static data! Think images, videos, files..
How it works is basically like the cache, but it is directly connected to the client, so there are no in-memory or disk round-trips (at least not to yours 😆)..
CDNs are provided by third-parties like Cloudflare, so you really need to be careful with their use.
They can be a very optimal and cheap way of retrieving static content, but they as easily become expensive. - think stale/not used data, overuse..
Message Queues
Adding message queues to a system can be a game-changer. Why?
Message Queues can offload big amounts of processing from the core service and process it in the background. How?
As seen on the image, message queues are a separate component, which works as the data structure Queue (in a FIFO manner).
With MQs we have the pub-sub concept, which means. Different components (micro-services) publish messages to the MQ. Others subscribe to these messages and do some processing upon consumption.
Some use-cases where MQs can be very helpful:
In running background tasks
In async processing - MQs are perfect for Event-Driven Architectures, as they provide eventual consistency
Processing of Big Data - i.e. when you need to give data to some data science service, which will use it for aggregation or some ML model. In this scenario they don’t need the data in the exact millisecond, so eventual consistency fits nicely!

Scaling Across Different Geo-Locations
Our user-base has grown, but it hasn’t done that only in Europe per say. We know have users from The USA, Asia.. Know the question becomes, how can we scale the app so that users across America and Asia get their data as quick as the ones in Europe? 🌍 👀
To achieve that:
We can leverage the different data centers around the globe via geo-routing. i.e. users can be automatically routed to the nearest data center to them
We have regions like US-East and US-West, to which traffic is routed based on the IP Address provided by the GeoDNS!
That way, in case of a failure (fire or earthquake) in one data center, traffic can be automatically routed to the nearest available data center - achieving higher fault-tolerance. Of course, in order to have the same data available across different locations around the globe we need to replicate if across the regions..
Logging / Monitoring
When you are working in a simple CRUD app, in monolithic environment, it’s rather easy to trace requests and debug.
That said, you still need to add some logs in your software to trace down some userId or productId, when a custom complains.
In a micro-service environment and as you scale to larger uses-bases, the importance of logging and monitoring becomes exponentially larger. Why? 🤔
when dealing with multiple services and you need to trace down a given user action, good luck doing that without distributed logging 😅
you have multiple machines, each handling a different DB cluster, how do you know what’s the state of CPUUtilization, RAM or Storage? You need smth like AWS Monitoring/CloudWatch
Product comes and asks what are our Daily Active Users for the Invoicing product of our app? Good luck providing that without some monitoring and tracing of user actions.
Point being, leverage tools like Grafana, Prometheus, DataDog in order to have this setup before it’s too late!
Final System Look 👀

Key Takeaways 🔑
To make it simpler, here is a To-Do list of the key things to consider if we wanna scale:
Scale Horizontally
Implement caching whenever possible
Choose your database wisely
Go stateless
If you have static content like images or videos, always use a CDN
Utilize async processing through message queues when feasible
Do you due-diligence in ensuring proper add logging and monitoring
I tried to keep it simple and insightful, yet easy for everyone to understand and dive-deeper if interested! 🚀
I am yet to read the System Design Book by Alex Xu & Sahn Lam from ByteByteGo, so stay tuned for more notes from myself! 🔜
Other System Design articles you may like




 | A guest post by
|