
Why gRPC Is Actually Fast: The Truth That Will Surprise You
How HTTP/2 enables true parallelism over a single connection


🏃♂️ GRAB IT NOW: 35% OFF Before It’s Gone Forever - 35% off on our paid subscription — limited-time offer, don’t miss out! Expiring Soon ..
Hello guys, When people talk about gRPC’s speed, the conversation almost always centers on Protocol Buffers (Protobuf) as the magic ingredient. While Protobuf’s compact serialization certainly helps, it’s not the whole story.
The real engine behind gRPC’s blazing performance is HTTP/2.
This next-generation protocol introduces features like multiplexed streams, header compression, and persistent connections, which dramatically reduce latency and improve throughput compared to traditional REST over HTTP/1.1.
Understanding why HTTP/2 matters is key to grasping what makes gRPC truly fast—and why it’s becoming the go-to choice for high-performance microservices.
For this article, I have teamed up with Sahil Sarwar, a passionate Software Engineer and we’ll dive into details about how HTTP/2 enables true parallelism over a single connection
By the way, if you are preparing for System design interviews and want to learn System Design in a limited time then you can also checkout sites like Codemia.io, ByteByteGo, Design Guru, Exponent, Educative, Bugfree.ai, System Design School, and Udemy which have many great System design courses

With that over to Sahil to take you through rest of the article.
I have always wondered, WHY gRPC is so fast, faster than traditional REST APIs, the answer goes beyond just “binary encoding” or “Protobuf”.
It’s deeper. It’s about how the protocol beneath it, HTTP/2, handles requests differently.
When I wanted to understand gRPC, all I could see were buzzwords like “stub”, “protobuf”, “HTTP/2”, “multiplexed streams” and other things that I didn’t really understand. So here is me actually breaking it down, piece by piece.
This is part 1 of the gRPC series, focusing on the shortcomings of HTTP/1.
In this post, I want to break down HTTP/2 multiplexing, how it solves the head-of-line blocking problem in REST, and why gRPC was designed to take advantage of it from the start.
No fluff. Just a clear, technical breakdown, what it is, how it works under the hood, and why it actually matters when we are building APIs that need to scale.
Disclaimer: This won’t be a detailed discussion about gRPC, I might cover it in another post.
The Problem — TCP Connections
To understand HOW a bottleneck is solved, we need to understand what the bottleneck even is.
Let’s take a look at what happens when a client does a network call to a server to get some resources back.
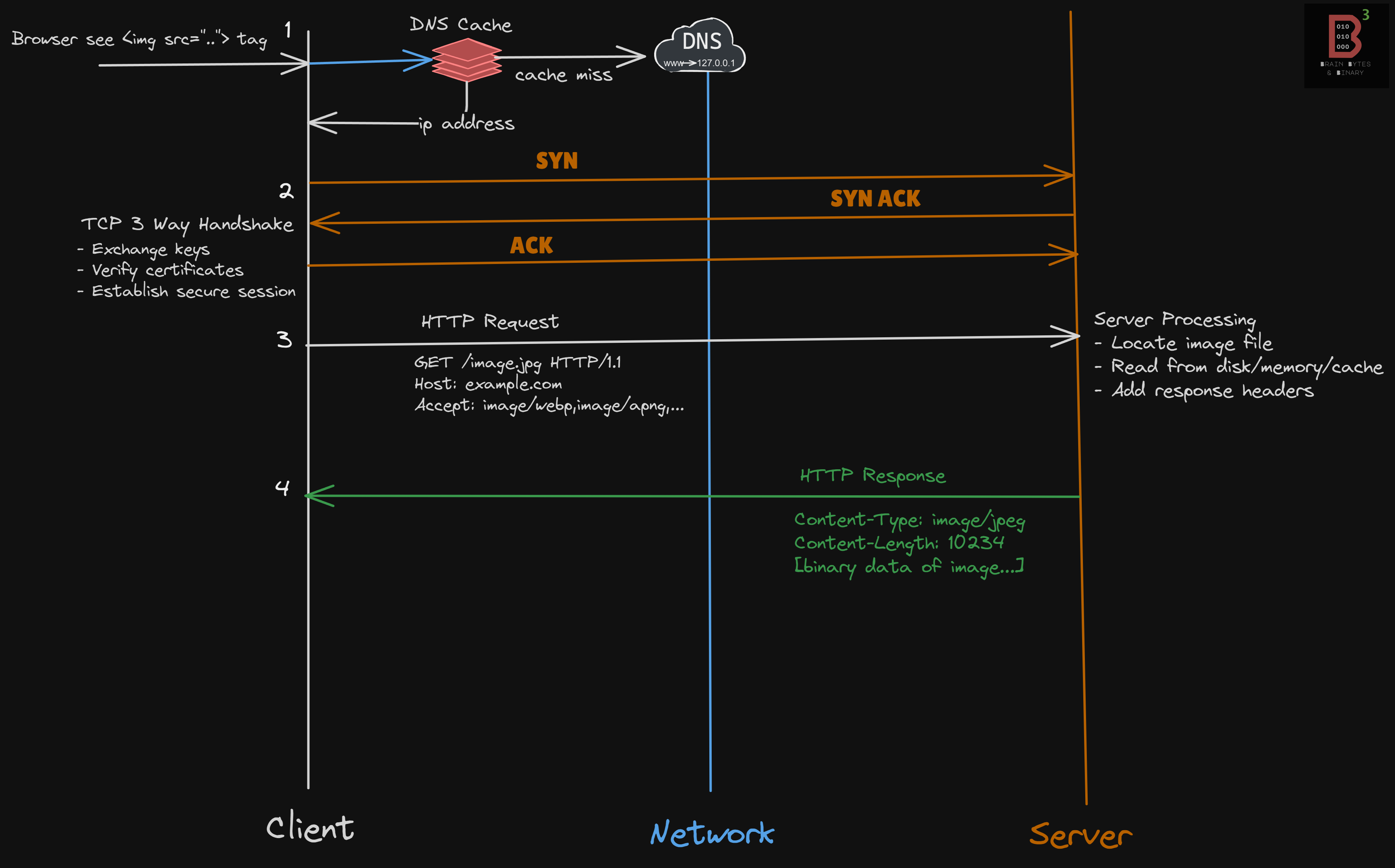
Let’s look at all these steps —
The browser sees something that it needs to fetch (e.g.,
<img src=”…”>tag)It will check if it has the IP address cached locally in the DNS cache; if not, it will call the DNS resolver to get the IP address
Now, the three-way TCP handshake begins, consisting of the usual SYN, SYN-ACK, and ACK.
If the connection is HTTPS, there are certain extra steps like verifying certificates, exchanging keys
The client sends the HTTP Request
The server locates the image, prepares the response headers, and sends the response
As we can see, each connection goes through all these steps to obtain just one image.
What if we have 20 images? Well, the only way to do it in HTTP/1.1 would be to create 20 TCP connections and get the data, right?
Well, yeah, kinda. However, creating those TCP connections is not efficient due to the way data is transmitted over TCP.
So, how does data get transmitted over TCP?
TCP Congestion Control
What’s a congestion? Well, it’s similar to what we know: when a lot of data reaches the server more than it can handle, that’s congestion.
The idea of TCP congestion control is for each source to understand how much capacity is available in the network, so that it knows how many packets it can safely have in transit.
Additive Increase/Multiplicative Decrease
TCP maintains a variable for each connection, called CongestionWindow, which is used by the source to limit how much data it is allowed to have in transit at a given time.
Decreasing the congestion window when the level of congestion goes up and increasing the congestion window when the level of congestion goes down. Taken together, the mechanism is commonly called additive increase/multiplicative decrease (AIMD).
Multiplicative Decrease
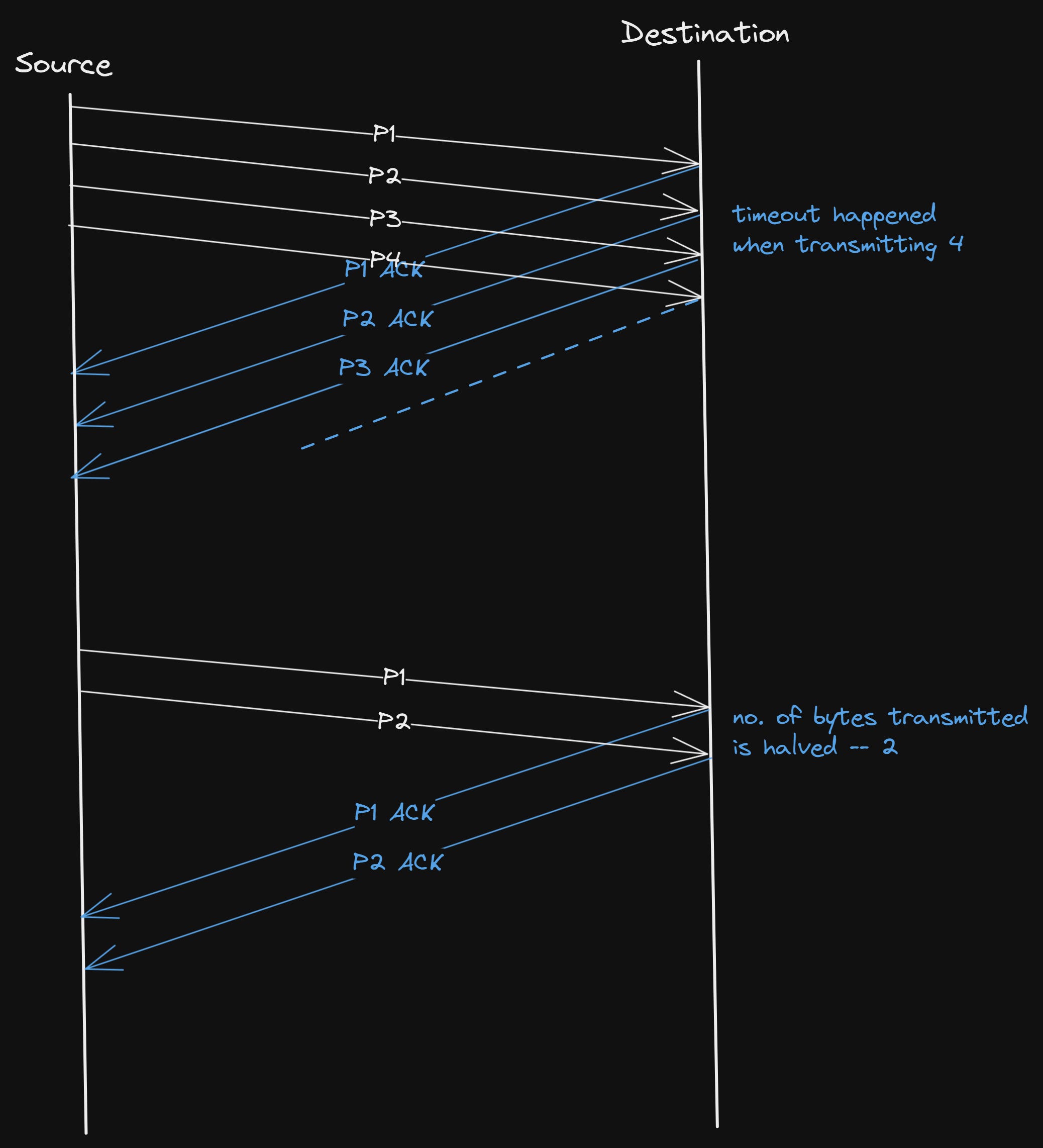
Whenever a timeout occurs in TCP, it treats it as a sign of congestion, and it reduces the rate at which data is transmitted.
More technically, it sets the CongestionWindow to half of its previous value. This halving of the CongestionWindow for each timeout corresponds to the “multiplicative decrease” part of AIMD.
It will be clearer with the following diagram —
Additive Increase
Every time the source successfully sends a CongestionWindow’s worth of packets, that is, each packet sent out during the last round-trip time (RTT) has been ACKed, it adds the equivalent of 1 packet to CongestionWindow.
Meaning, we increase it linearly, that’s why the name “additive increase”.

But why? Why are we decreasing the CongestionWindow by half when packets are dropped, but only increasing it linearly when they are accepted?
This is because when the window is too large, packets that are dropped will be retransmitted, making congestion even worse. It is important to get out of this state quickly.
That’s why it’s better to decrease the no. of packets transmitted quickly to decrease the congestion.
But what happens when the TCP just starts sending the packets?
If we follow the above “additive increase” way, it will take forever to reach the full capacity of the network. We need to send more packets initially to ramp up the network to its full capacity.
But how many packets should it send at the start? How does the host know what the “safe” CongestionWindow initially is?
Slow Start
As we discussed, if we use the same “additive increase” algorithm initially, and begin by using the CongestionWindow = 1, then it would be a waste of time. So, we do something better.
Instead of “additive increase”, we do an exponential increase —
Source starts by setting
CongestionWindow= 1.When the ACK for this packet arrives, TCP adds 1 to
CongestionWindowand then sends two packets.Upon receiving the corresponding two ACKs, TCP increments
CongestionWindowby 2—one for each ACK—and next sends four packets.The result is that TCP effectively doubles the number of packets it has in transit every round trip

So, it increases exponentially, but once it starts dropping packets, CongestionWindow will decrease exponentially, and after that, it will be an additive increase, and the cycle repeats.
So, now we know that creating those 20 TCP connections to download 20 images is not only inefficient, but it’s quite heavy on the network.
There will be a lot of congestion, and the risk of dropping packets increases, which in turn increases the risk of getting more congestion.
This is the reason why most modern browsers only support creating 6-10 TCP connections to a server at a time.
Head-of-line blocking
But why are we closing the TCP connection? What if we don’t close the connection and use the same connection if the server is the same?
Well, that’s one solution; that’s what most modern browsers do now by default in keep-alive.
But here’s the catch: even if we reuse the existing TCP connections, the requests are queued. Let me explain it with an example.
Let’s assume we want 3 images from the server, the client sends these 3 requests to the server -
GET
/image1.pngGET
/image2.pngGET
/image3.png
The server “must” respond to image1.png before returning others, even if it can return image3.png faster. Meaning, if serving image1.png is slow — all the requests behind it are also blocked.
This is known as head-of-line blocking.
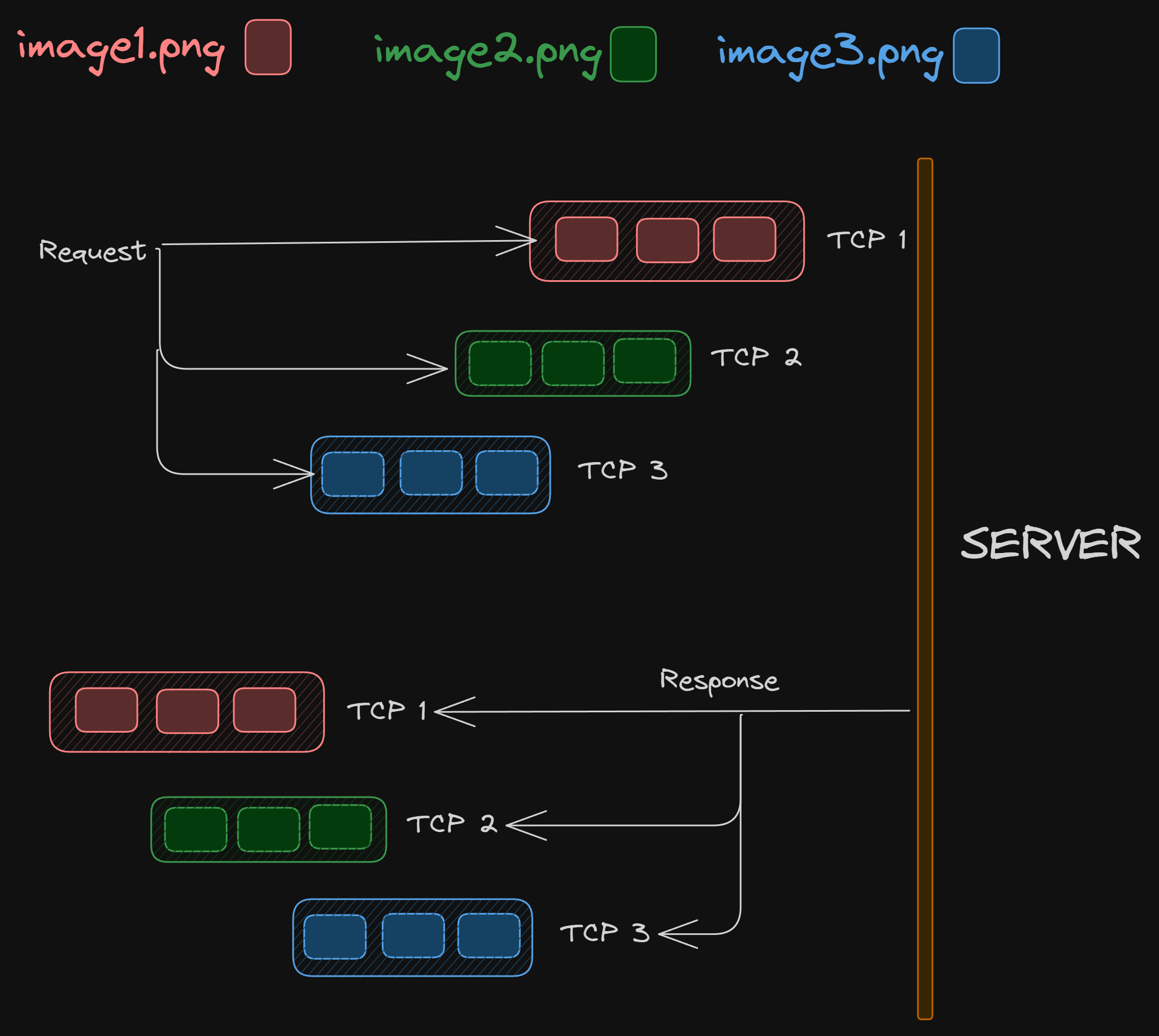
But why is that? Why can’t the server return image3.png first when it can serve it faster?
The reason lies in how HTTP/1.1 is designed. The client has no way to match responses to requests out of order, so the server must return things in order.
So, these are the bottlenecks that HTTP/1.1 has. It does seem obvious why this is a bottleneck when designing applications that require scale and low latency.
Note: While this is a transport-level issue (TCP), it directly impacts how efficiently HTTP/1.1 handles multiple resource requests.
Let’s see how we can improve on this bottleneck of HTTP/1.
HTTP/2 — Multiplexed Streams
Well, that’s a fancy word; let’s understand what it means.
So we saw that to get 3 different images, we needed 3 TCP connections to the server, and each of them is blocking the others behind them.
What if instead of sending those images over different TCP connections, we send them over a single one?
Well, that would be a problem, because HTTP/1.1 doesn’t know how to map those requests. That’s what HTTP/2 solves — it knows HOW to map these streams when getting the response back.
Think of it this way -
There is a multi-lane highway, where cars of different colours are travelling
The cars can be in random order, of course
But when they reach a parking lot, they are arranged by their colour, kind of like a map

There is only a single TCP connection being utilised, but multiple streams can exist within a single TCP connection.
Each stream is a bi-directional, independently flow-controlled virtual channel.
So, what does it solve? Well, all the problems that we saw above, well, almost.
Solving TCP Congestion
If we need 5 different images, no need to use 5 different TCP connections; we can just use 1 TCP connection, and all 5 images can be different streams, independently.
This reduces the load on the network, making sure congestion is less.
Reducing Latency
Since all the packets are shared over a single socket, parallelism is achieved, and it reduces the latency of managing multiple connections and handling them separately.
Solving head-of-line blocking? Not quite
Since there are multiple streams in a single TCP connection, meaning no other resource has to wait for requests in front of them to get completed, as they are independent streams.
But if some of those packets are dropped, they need to be retransmitted, meaning all other packets are blocked until the dropped packets are retransmitted. Meaning, head-of-line blocking is not solved completely.
This again is solved in HTTP/3, we can look at HOW in some future posts.
Wrapping Up
So now we know, it’s not just “Protobufs” or “gRPC is binary.”
It’s the underlying transport, the evolution of HTTP/2, and how it unblocks the limitations of HTTP/1 by design.
Multiplexed streams, reduction of head-of-line blocking, and better use of a single TCP connection are not just minor tweaks.
They’re fundamental shifts in how modern APIs perform at scale.
And gRPC was built from the ground up to exploit these benefits.
In future posts, I’ll dig deeper into how gRPC works, how it models services, how streaming works, how it builds on HTTP/2, and where it shines (and also where it doesn’t).
That’s it for this week, see you next week with something more interesting.
Stay tuned!
And, if you like this article, don’t forget to subscribe to Sahil’s newsletter , “Brain, Bytes and Binary” where he shares his thoughts on system design and programming.

References
I came across an amazing article about TCP Congestion Control. The algorithm is so beautiful, and it has been explained in such detail in this one. I highly recommend reading it if you have some time this weekend.
Other System Design Articles you may like





🏃♂️ GRAB IT NOW: 35% OFF Before It’s Gone Forever - 35% off on our paid subscription — limited-time offer, don’t miss out! Expiring Soon ..
 | A guest post by
|