


System Design Basics - Databases and Connection Pools
Why more open connections can degrade your queries?


Celebrate 4th of July with 35% off on our paid subscription — limited-time offer, don’t miss out! Expiring Soon ..
Hello guys, when designing scalable systems, one of the most critical components to understand is the database layer and how applications interact with it efficiently.
Whether you're building a monolithic backend or a distributed microservices system, the performance and reliability of your database connections can make or break your application.
Earlier I have talked about essential system design concepts like Rate Limiter, Database Scaling, API Gateway vs Load Balancer, Horizontal vs Vertical Scaling, Forward vs reverse proxy as well common System Design problems like URL shortener and Spotify design.
And, this post introduces you to two foundational concepts—Databases and Connection Pools—and explores how they work together to handle millions of requests while ensuring optimal performance, fault tolerance, and resource management.
Whether you're preparing for a system design interview or building high-performance systems in production, understanding database and connection pool is key to mastering robust system architecture.
For this article, I have teamed up with Sahil Sarwar, a passionate Software Engineer and we'll dive into the fundamental concepts of Cache invalidation, Why its difficult, timeliness vs accuracy, constraints, and tradeoffs.
By the way, if you are preparing for System design interviews and want to learn System Design in a limited time then you can also checkout sites like Codemia.io, ByteByteGo, Design Guru, Exponent, Educative, Bugfree.ai, System Design School, and Udemy which have many great System design courses

With that its over to
to take you further.Before we dive into the internals of connection pools, let’s first understand what they are and WHY they are essential in modern backend systems.
We’ll begin by exploring the implications of establishing new database connections for every query, and how connection pools reduce that cost.
Once we have a solid understanding of their purpose and mechanics, we’ll investigate what happens when we increase the number of open connections in a pool, looking at the performance and trade-offs involved.
Finally, we’ll do some experiments to establish the effects of changing max open connections for the database and examine its results.
For more context on the inspiration for this blog, please take a look here.
The Need for Connection Pools
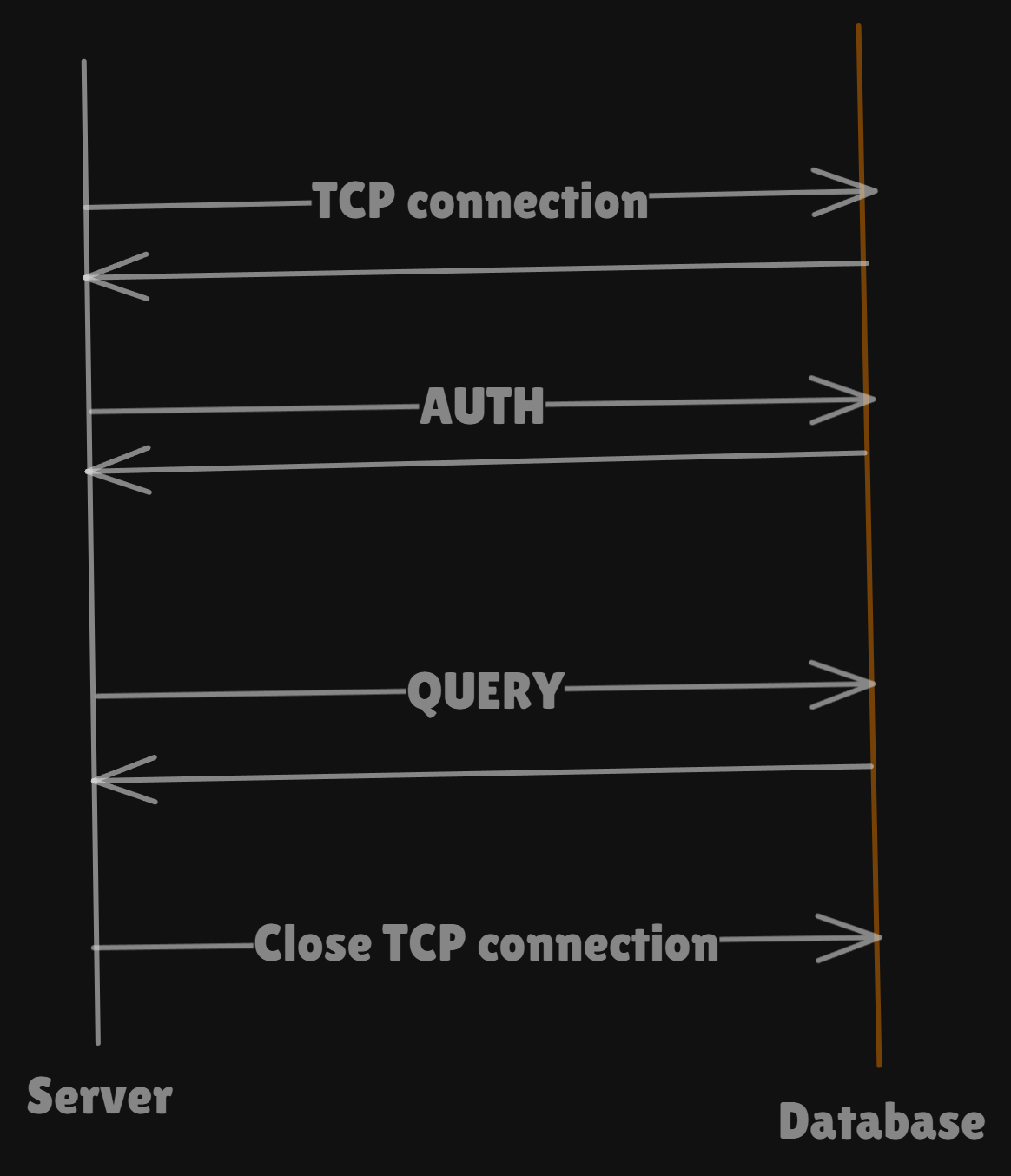
Every query that our backend does to the database has to go through this 3-step process —
Establish a TCP connection and authenticate with the database
Run the query with the established database
Parse the result and close the connection
Now consider this for a database running millions of queries per second.
Establishing a TCP connection includes a 3-way handshake, SSL negotiation, and authentication. Repeating this for every query introduces ~10–100ms of overhead per call, which scales into bottlenecks at high queries per second.
This is inefficient, as creating and tearing down a connection for every query introduces significant latency and load on the DB.
So, can we do something better?
If we look closely, how about we always keep some of the connection open, meaning, it will always have a TCP connection that is authenticated and ready for query execution.
And we can reuse these for different queries. That’s exactly what a connection pool is.
Connection Pools
The backend always asks the database to keep a certain no. of connections ready in the “pool”.
Now, every time the backend needs to perform a query —
Checks the pool and gets a free connection (no need for TCP connection/Authentication)
Run the query with that connection
Parse the result, and return the connection to its pool (doesn’t need to close the connection)

This not only puts less load on the database, but also improves the concurrency of the application, which in turn decreases our query response time.
Since we are using existing connections, we don’t need to perform the extra steps of TCP open/close and authentication.
Max Open Connections
When we create a connection pool, we can configure the maximum number of open connections that can be maintained at a time in our pool. This is commonly known as “max open connections”.
This is an important parameter that affects the performance of our queries and the load on the database.
While working on a problem, I was trying to do a load test on our database —
Create a connection pool
Configure multiple goroutines to run a specific query
Monitor the response time and database performance
Here are my observations —
The initial few goroutines were running the query in ~80ms
As we get to more goroutines, the query is taking longer and longer
For around 100 goroutines, it took a total time of ~1.2 sec, which was a lot for that query

This hinted that there must be some kind of contention going on between the goroutines for acquiring the connection, but I wasn’t exactly sure.
I looked at the database dashboard, I saw a sudden spike in latency, commit throughput, max database connections, and other parameters.
Max Open Conn = 0 → Infinite
When I looked at the connection pool config, I found that we were setting the db.SetMaxOpenConns(0) which meant that the no. of open connections at a time can be infinite.
I thought of tweaking this value and seeing the response to this change.
Max Open Conns = 5
I changed to db.SetMaxOpenConns(5) and these were the results —
The initial few goroutines were still taking ~80ms
But as the goroutines increased, there was just a slight decrease in the query time
For 100 goroutines, it now takes just ~120ms
I looked at the database dashboard, and there were no sudden spikes, no latency increase, and other parameters were normal.
So, what’s happening?
Effect of Open Connections on Database
1. OS Level Limits
Every DB connection = 1 OS-level TCP socket + memory
File Descriptor Limit: OS typically caps open sockets per process (e.g., 1024 in Linux by default).
Context Switching: More connections = more kernel threads = higher CPU usage for scheduling.
2. Postgres Backend Process Model
Each client connection in PostgreSQL spawns a dedicated backend process.
Each connection = ~10 MB+ memory per process.
No thread-pooling or shared handling.
Infinite connections = infinite processes = memory exhaustion + high CPU + OS scheduling overhead.
3. Connection Pool Exhaustion vs. Saturation
When we allow infinite connections, we’re not queuing or reusing them:
DB CPU saturation: All queries compete for CPU and disk I/O.
Buffer cache thrashing: Too many clients lead to frequent cache invalidation.
Lock contention: More parallel connections = higher chance of row/table lock waits.
4. PostgreSQL Locking & Internal Limits
max_connections (default ~100) exists to avoid fork bombs.
Exceeding it causes query failures, but even below the cap, performance drops significantly when active sessions grow.
Performance Analysis
I wanted to replicate what I found earlier while working on a problem at work, so I did the following experiment locally —
Create a connection pool with PostgreSQL, there are 2 configurations.
MaxOpenConns = 20 (finite)
MaxOpenConns = 0 (infinite)
Create 200 goroutines, each of which will get the connection from the pool
Each of them will perform the query on the database

Benchmark Results
When I tried replicating the behavior that I found initially, I couldn’t exactly replicate it. Maybe it was the environment that I was testing earlier, which I was not able to recreate locally, or it was some other parameters, but it just didn’t work.
Regardless, these were the benchmark results —


If we look at the latencies of the limited pool, we observe a pattern —
Since our maxOpenConn = 20, we see that all the other goroutines are blocked; that’s why we see that each of these is distributed in groups of 20.

Conclusion
This experiment reveals a crucial reality about connection pooling:
Unbounded
maxOpenConnsisn't a performance hack; it’s a hanging gun.Allowing all goroutines to open their connections leads to rapid saturation of the database’s
max_connectionslimit.While the system may seem faster due to early query failures (as in our ~0.13s average), this comes at the cost of failed requests, resource thrashing, and potential DB crashes.
On the other hand, setting a reasonable cap (like maxOpenConns = 20) introduces queuing, yes, it increases our average (~0.6s in our case), but it ensures:
All queries succeed
The DB remains healthy
The system remains predictable under load
In real systems, throughput, stability, and success rate matter far more than raw latency.
If we are building high-load services, we should consider the following:
Profile the DB limits (
max_connections, memory, CPU)Tune the pool size accordingly
Never go unbounded unless we want downtime
Wrapping Up
In this post, we dove deep into how connection pooling directly affects query performance, system stability, and overall throughput in a Go + Postgres setup.
By simulating concurrent workloads with different maxOpenConns values, we observed:
Finite connection pools (e.g.,
maxOpenConns = 20) enforce backpressure, increasing latency but maintaining stability and success rates.Unbounded connection pools (
maxOpenConns = 0) can overload the database, leading to fast but failing requests.
We backed this with:
Real benchmark data
Failure rate observations
This hands-on exploration not only demonstrates why blindly increasing concurrency is harmful but also emphasizes the need for tuning the connection pool according to the DB’s limits and expected load.
That’s all for this one, I will be back with another interesting take next week.
Stay tuned!
And, if you like this post, don’t forget to subscribe Sahil’s newsletter Brain Bytes and Binary, where he share his experience on system design and architecture

Other System Design Basics Articles you may like




 | A guest post by
|